










While building AI-powered tools, developers and researchers constantly seek more efficient, accurate, and scalable methods to tailor AI models to specific tasks. Two notable approaches have emerged lately – Retrieval-Augmented Generation (RAG) and Fine-tuning.
In this guide:
- Introduction to RAG and Fine-tuning
- What is Retrieval-Augmented Generation (RAG)?
- What is Fine-tuning?
- Comparison of RAG and Fine-tuning
- Applications
- Choosing Between RAG and Fine-tuning
More than few aspects need consideration when building AI-powered solutions with ready-made models (like open-source LLM’s). You can fine-tune the model to achieve the highest possible performance, on the downside, risking overfitting. Retrieval-Augmented Generation can add specific industry knowledge, but won’t add functionality.
There is also a possibility to blend both. Let’s delve into the nuances of RAG and Fine-tuning, comparing methodologies, applications, advantages, and limitations.
Introduction to RAG and Fine-tuning
Key differences between RAG and fine-tuning lay in the foundational concepts, targeted results and – at the end – possible business application.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation combines the power of neural networks with external knowledge bases or databases to enhance the generation of responses or content. In RAG, a query is first used to retrieve relevant information from a database. This information is then fed into a generative model, such as GPT (Generative Pre-trained Transformer), to produce a contextually enriched output.
This approach allows the model to leverage vast amounts of data beyond its initial training set, making it particularly useful for tasks requiring up-to-date or specialized knowledge.
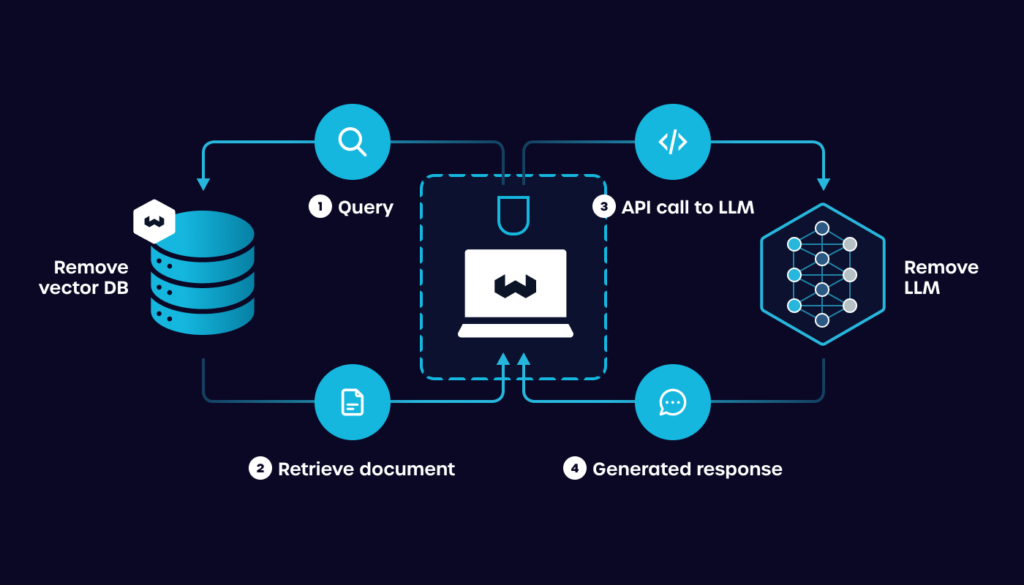
For RAG solutions to work, you’ll need vector database embeddings. Topics we cover in other publications.

Advantages of RAG:
- Accuracy and Relevance. By retrieving relevant information during generation, RAG can produce more accurate and contextually relevant responses, especially for knowledge-intensive tasks.
- Dynamic Knowledge. Unlike static pre-trained models, RAG can access the most recent information available in its retrieval database, allowing it to provide up-to-date responses.
- Scalability. The retrieval component can be scaled independently of the language model, allowing for efficient handling of large information sources.
Considerations of RAG:
- Latency. Retrieval from large databases can add latency to the generation process.
- Data Dependency. The quality of the generated output heavily depends on the quality and relevance of the retrieved documents.
What is Fine-tuning?
Fine-tuning, on the other hand, involves adjusting the weights of an already pre-trained model on a new, typically smaller, dataset specific to a target task. This process allows the model to transfer the general knowledge it has learned during pre-training to the nuances of the new task.
GOOD TO KNOW:
Fine-tuning is widely used across various AI applications, from natural language processing (NLP) to computer vision, due to its efficiency in adapting large models to specific needs with relatively minimal additional training.
Advantages of fine-tuning:
- Efficiency. Fine-tuning requires less computational resources than training a model from scratch, as it leverages pre-learned representations.
- Flexibility. It can be applied to a wide range of tasks, including text classification, sentiment analysis, question answering, and more.
- Performance. Often achieves high performance on the target task due to leveraging large-scale pre-trained models.
Considerations of fine-tuning:
- Overfitting. There’s a risk of overfitting to the smaller dataset, especially if it’s not diverse or large enough.
- Data Sensitivity. The performance can significantly vary based on the quality and quantity of the task-specific data.
Comparison of RAG and Fine-tuning
The core difference between RAG and fine-tuning lies in their approaches to leveraging external information. RAG dynamically incorporates information from external sources at inference time, while fine-tuning integrates new information during the training phase, modifying the model itself to better perform on the target task.
Applications
RAG excels in applications where access to vast, constantly updating databases is necessary, such as in question-answering systems, content creation, and scenarios requiring specialized knowledge.
Fine-tuning, conversely, is preferred for tasks where a solid base model can be specialized to a particular domain or style, like sentiment analysis, image recognition, or language translation.
Advantages
RAG's primary advantage is its ability to utilize up-to-date information, making it ideal for tasks requiring the latest knowledge. Additionally, since it leverages external databases, it can handle a broader range of queries without needing to retrain the model.
Fine-tuning, meanwhile, offers a more straightforward path to customizing models for specific tasks, often requiring less computational resources than training a model from scratch. It allows for profound customization, as the entire model's weights are adjusted to optimize performance on the target task.
Limitations
The success of RAG depends heavily on the quality and scope of the external database, as well as the efficiency of the retrieval mechanism. It can also be computationally intensive, especially for large databases.
Fine-tuning, although resource-efficient compared to full training, still requires significant computational power and data for optimal results. There's also a risk of overfitting to the fine-tuning dataset, potentially reducing the model's generalizability.

Choosing Between RAG and Fine-tuning
The choice between RAG and fine-tuning hinges on specific project needs:
- RAG is preferable for applications needing access to a wide array of up-to-date information, or when the task requires pulling in specialized knowledge from large databases.
- Fine-tuning is ideal for customizing models to specific tasks when there's a reliable pre-trained model available and the task can benefit from deep, task-specific adjustments.
Both methods have their place in the AI development toolkit, and understanding their strengths and limitations is key to leveraging them effectively.
All depends on your needs
Retrieval-Augmented Generation and fine-tuning represent two powerful, albeit distinct, approaches to customizing AI models for specific tasks. RAG shines in scenarios requiring real-time access to extensive databases, providing AI models with a wealth of information to draw from.
Fine-tuning, in contrast, offers a more traditional yet highly effective method of tailoring pre-trained models to achieve superior performance on particular tasks. The choice between them depends on the specific requirements of the task at hand, including the need for up-to-date information, the availability of relevant pre-trained models, and the computational resources at one's disposal.
By carefully evaluating these factors, developers, and researchers can select the most appropriate strategy to enhance their AI systems, pushing the boundaries of what's possible with current technology.

Frequently Asked Questions
What is the main advantage of RAG over traditional methods?
The main advantage of RAG is its ability to dynamically incorporate vast amounts of external, potentially up-to-date information into the model's output, enhancing the quality and relevance of the generated content.
Can Fine-tuning be applied to any pre-trained model?
Yes, Fine-tuning can be applied to any pre-trained model, provided there's a sufficient amount of task-specific data available to retrain the model effectively for the new task.
Is RAG more computationally intensive than Fine-tuning?
Generally, RAG can be more computationally intensive than Fine-tuning, especially if it involves large external databases and complex retrieval mechanisms. However, the specific computational requirements depend on the scale of the task and the efficiency of the implementation.
How do you prevent overfitting during Fine-tuning?
To prevent overfitting during Fine-tuning, it's crucial to use techniques such as regularization, cross-validation, and early stopping. Additionally, fine-tuning with a diverse and sufficiently large dataset can help ensure the model retains its generalizability.


