











When implementing AI-based projects, it’s valuable to have a basic understanding of several concepts related to building these types of solutions. This knowledge helps in communication with subcontractors and in understanding one’s own needs. We delve into vector databases, closely associated with artificial intelligence.
Table of Contents:
- Why Do We Need a Vector?
- How is a Vector Database Created?
- What Are Vector Databases?
If you’ve encountered terms like vector database, vector embeddings, or Pinecone and want to know what they really mean — you’re in luck. Although creating projects based on machine learning doesn’t require the use of vector databases, they are particularly popular in LLMs (Large Language Models) and often mentioned in the media, making them worth exploring.
Remember, the foundation of every machine learning project should primarily be business objectives and the data we work with. Before deciding to create a database, it’s wise to consider if it is essential for the project’s realization.
Vector databases themselves are an interesting and expansive topic, here presented in a simplified, digestible version.
Why Do We Need a Vector?
At the heart of every AI project lies data. The better the data, the higher the solution’s efficacy, and the well-worn phrase “data is the new oil” didn’t come from nowhere. Those in technology are certainly familiar with SQL tables, hierarchically segregated data, or object data.

Traditional methods of information search (e.g., string search) involve checking if a sought-after element is in the database. A limitation is that if you’re not searching for a specific item, a traditional database will be limited.
Vector databases allow for searches based on the semantic proximity of data points, and a vector representation of data can have many features. That’s why they’re so popular in ML and AI solutions
Creating vectors from data is a process that allows for transferring semantic relationships into the numerical world. You encounter vector databases regularly… using Google Search or recommendation systems in online stores.
To stir your imagination: Imagine a two-dimensional space in the form of a chart with X and Y axes. Your data is mapped onto this space. Let’s say there are 10 data points, as shown in the chart below. Each data point has a corresponding number on the X and Y axes, i.e., a two-dimensional vector.
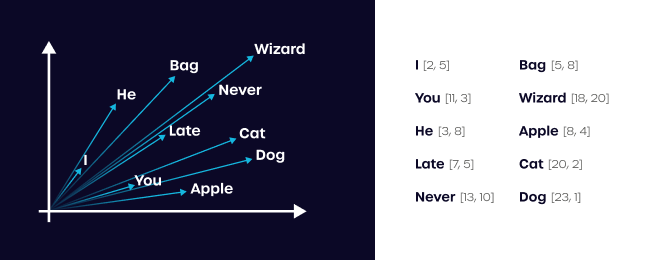
The task of assigning numerical values to data features is precisely what embedding is about. What’s most interesting is that data described by neural networks often have a much higher number of “dimensions,” possibly reaching up to 2000. The relationship between data points can be defined in terms of distance.
For instance, nearest to the word “cat” in the group below will be (where 1 = the same word):
- dog 0.8
- fox 0.75
- squirrel 0.5
- chicken 0.2
Based on information about the semantic proximity of vectors, AI/ML models can create responses to queries.
This principle applies to all solutions, especially text-based ones, that respond to your query by finding semantic proximity in the database.
How is a Vector Database Created?
The process of converting data into vectors is called embedding (vector embedding) and can be done in several ways, depending on the requirements. In theory, you could involve a specialist from the relevant field.
Suppose we need to prepare a database of motorcycle photos and engage a motorcycle industry expert to assist in describing them. The expert would design a set of features, like motorcycle type, wheel size, presence, or absence of fairings, brand. Based on this, a database is created where the brand “Ducati” (Italian sports motorcycles) would be closer to “sports motorcycles” than, say, Harley-Davidson, which doesn’t offer such motorcycles.
The problem with this approach is the significant costs, especially with larger datasets. Therefore, pre-built solutions, specifically neural networks, are often used.
Vectors are mathematical representations of data designed to facilitate, not complicate, work. It's crucial to assess whether creating a vector database is necessary for the project and has a business foundation.
Then there are further options: creating your own model for data generation or using pre-built ones. It's no secret that dedicated neural networks for vector creation are highly effective, and often, there are ready-made solutions for creating vectors for specific types of data (e.g., BERT for text, CNN networks for images).
If you're still interested, be sure to check out the following video, discussing text embedding for NLP (Natural Language Processing) solutions:
What Are Vector Databases?
As you might guess, vector databases are used for storing… vectors. Such data is very useful in natural language processing (NLP), recommendation models, and semantic searching.
They also have other advantages:
- Efficient data processing. They can quickly process large amounts of data. This is due to a method called “vectorization,” which allows them to perform operations on entire datasets at once, rather than on individual elements.
- High performance. Due to their structure, vector databases offer high efficiency. They can handle complex queries and computations faster than traditional databases.
- Scalability. They can easily manage increasing amounts of data without significant performance degradation. There are ready-made databases available on the market, including Pinecone, Weaviate, or the open-source Chroma.
The possibilities are endless. Vector databases are useful when building an internal company chatbot or a recommendation system for your customers. To execute an AI-based project, you need high-quality data, an idea, a business goal, and a small team of specialists. The range of open-source solutions, dedicated paid solutions, and frameworks from tech giants (e.g., Google's Vertex AI) allows for very effective project implementation.

Frequently Asked Questions
What are vector databases, and what is their application?
Vector databases are specialized databases primarily used in Natural Language Processing (NLP), recommendation models, and semantic searching. They store vectors, which are mathematical representations of data, facilitating the rapid processing of large quantities of information.
How is a vector database created?
Creating a vector database, known as the embedding process (vector embedding), can be carried out in various ways depending on the needs. It can involve engaging specialists to manually design data features, or using ready-made solutions and neural networks that automatically generate vectors based on the data.
Why are vectors important in AI projects?
Vectors are crucial in AI because they enable efficient and fast data processing. They allow for semantic searching and data analysis, especially useful in solutions based on NLP and recommendation models. Vectors transform complex data into a format that is easier to analyze and process by AI models.


