











Podczas tworzenia narzędzi napędzanych przez sztuczną inteligencję, deweloperzy stale poszukują bardziej efektywnych, dokładnych i skalowalnych metod dostosowywania modeli AI do konkretnych zadań. Na dwa podejścia warto zwrócić uwagę: Retrieval-Augmented Generation (RAG) i fine-tuning.
W tym artykule:
- Wprowadzenie do RAG i fine-tuning
- Czym jest Retrieval-Augmented Generation (RAG)?
- Czym jest fine-tuning?
- Porównanie RAG i fine-tuningu
- Zastosowania
- Zalety obydwu rozwiązań
- Ograniczenia
- Wybór między RAG a fine-tuningiem
- Wszystko zależy od Twoich potrzeb
Budowanie rozwiązań opartych o AI wymaga uwzględnienia masy aspektów – także, jeśli pracujesz z gotowymi modelami open-source. Dostrojenie modelu, czyli tak zwany fine-tuning, pozwoli zwiększyć wydajność w danej kategorii zadań, ale ryzykujesz overfittingiem. Z drugiej strony Retrieval-Augmented Generation (RAG) może dodać specyficzną wiedzę branżową, ale nie zwiększy funkcjonalności.
Istnieje również możliwość połączenia obu podejść. Zagłębmy się w niuanse RAG i fine-tuningu, porównując metody, zastosowanie, zalety i ograniczenia.
WARTO WIEDZIEĆ:
Overfitting oznacza, że model posiada bardzo wysoką skuteczność na danych, na których był szkolony, ale nie dla nowych danych – algorytm jest zbyt precyzyjny.
Wprowadzenie do RAG i fine-tuning
Kluczowe różnice między RAG a dostrajaniem modeli leżą u koncepcyjnych podstaw.
Czym jest Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation pozwala połączyć model z zewnętrznymi bazami wiedzy lub bazami danych, aby wzbogacić generowanie odpowiedzi lub treści. W RAG zapytanie jest najpierw używane do pobrania istotnych informacji z bazy danych. Te informacje są następnie wprowadzane do modelu generatywnego, takiego jak GPT (Generative Pre-trained Transformer), aby wyprodukować odpowiedź wzbogaconą od kontekst.
To podejście pozwala modelowi wykorzystać ogromne ilości danych poza początkowym zbiorem treningowym, co jest szczególnie przydatne do zadań wymagających aktualnej lub specjalistycznej wiedzy.
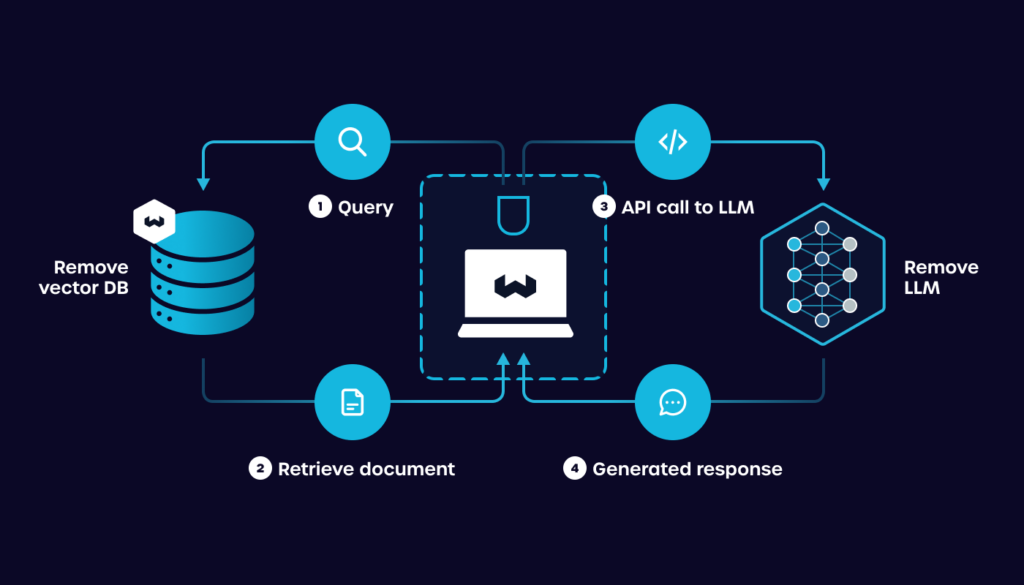
Aby rozwiązania RAG działały, będziesz potrzebował/a wektorowych bazy danych. Tematy te omawiamy w innych publikacjach.

Zalety RAG:
- Dokładność. Poprzez pobieranie istotnych informacji podczas generowania, RAG może produkować dokładniejsze i oparte o specyficzny kontekst odpowiedzi, zwłaszcza w zadaniach wymagających dużej wiedzy.
- Dynamicznie rosnąca wiedza. W przeciwieństwie do statycznych pre-trenowanych modeli, dzięki RAG wiedza może być na bieżąco aktualizowana (np. poprzez dodanie nowych plików do bazy).
- Skalowalność. RAG może współpracować z dużymi bazami danych.
Wady RAG:
- Prędkość działania. Pobieranie informacji z dużych baz danych może spowodować opóźnienie w procesie generowania.
- Skuteczność zależna od jakości danych. Jakość wygenerowanego wyniku w dużej mierze zależy od jakości i relewantności pobranych informacji.
Czym jest fine-tuning?
Fine-tuning polega na dostosowaniu parametrów już wstępnie wytrenowanego modelu do nowego, zazwyczaj mniejszego, zbioru danych specyficznego dla danego zadania. Ten proces pozwala modelowi przenieść ogólną wiedzę, którą zdobył podczas wstępnego trenowania, do niuansów nowego zadania.
WARTO WIEDZIEĆ:
Dostrojenie jest powszechnie stosowane w różnych aplikacjach AI, od przetwarzania języka naturalnego (NLP), po widzenie komputerowe. Popularność wynika głównie ze względu na efektywność metody w dostosowywaniu dużych modeli do konkretnych potrzeb.
Zalety fine-tuningu:
- Efektywność. Dostrojenie wymaga mniejszych zasobów obliczeniowych niż trenowanie modelu od zera. Niski koszt przy wysokiej skuteczności.
- Elastyczność. Metoda może być stosowana do szerokiego zakresu zadań, w tym klasyfikacji tekstu, analizy sentymentu, odpowiadania na pytania i innych.
- Wydajność. Fine-tuning osiąga wysoką skuteczność, dzięki wykorzystaniu modeli pretrenowanych na ogromnych zbiorach danych,
Wady fine-tuningu:
- Overfitting. Istnieje ryzyko nadmiernego dopasowania do mniejszego zbioru danych, zwłaszcza jeśli nie jest on wystarczająco zróżnicowany lub duży.
- Jakość danych. Skuteczność może znacząco się różnić w zależności od jakości i ilości danych specyficznych dla zadania.
Porównanie RAG i fine-tuningu
Główna różnica między RAG a trenowaniem polega na podejściu do wykorzystywania zewnętrznych informacji. RAG dynamicznie osadza informacje żeby poprawić wynik zapytania, podczas gdy dostrojenie integruje nowe informacje podczas fazy treningu, modyfikując sam model w celu lepszej wydajności w zadaniu docelowym.
Zastosowania
RAG sprawdzi się w miejscach, gdzie konieczny jest dostęp do ogromnych, ciągle aktualizowanych baz danych, takich jak systemy odpowiadania na pytania i tworzenie treści. Natomiast fine-tuning jest preferowany do zadań, gdzie solidny model bazowy zostanie wyspecjalizowany do określonej dziedziny, jak np. analiza sentymentu, rozpoznawanie obrazów czy tłumaczenie.
Zalety obydwu rozwiązań
Główną zaletą RAG jest możliwość wykorzystania zmieniających się informacji. Co więcej, ponieważ korzysta z zewnętrznych baz danych, może obsługiwać szerszy zakres zapytań bez konieczności ponownego trenowania modelu.
Fine-tuning z kolei oferuje skuteczny sposób na dostosowanie modelu do konkretnych zadań i pozwala na głęboką personalizację, ponieważ parametry całego modelu są zmienione.
Ograniczenia
Sukces RAG zależy w dużym stopniu od jakości i zakresu zewnętrznej bazy danych, a także efektywności mechanizmu wyszukiwania. RAG może być intensywny obliczeniowo, zwłaszcza dla dużych baz danych.
Fine-tuning wymaga znacznej mocy obliczeniowej i dobrej jakości danych dla optymalnych wyników. Istnieje także ryzyko nadmiernego dopasowania (overfittingu), co potencjalnie może obniżyć skuteczność.
Wybór między RAG a fine-tuningiem
Wybór między RAG a fine-tuningiem zależy od konkretnych potrzeb projektu:
- RAG jest preferowany do aplikacji, które wymagają dostępu do szerokiej gamy aktualnych informacji, lub gdy zadanie wymaga wykorzystania specjalistycznej wiedzy z dużych baz danych.
- Fine-tuning jest idealny do dostosowywania modeli do konkretnych zadań, gdy dostępny jest wstępnie przetrenowany model.
Obie metody mają swoje miejsce w biznesie. Oczywiście, istnieje możliwość dostrojenia modelu do potrzeb narzędzia i późniejsze korzystanie z metody RAG.
Wszystko zależy od Twoich potrzeb
Retrieval-Augmented Generation i fine-tuning reprezentują dwa różne podejścia do dostosowywania modeli AI do konkretnych zadań. RAG świetnie sprawdza się w scenariuszach wymagających dostępu w czasie rzeczywistym do obszernych baz danych. Fine-tuning natomiast oferuje bardziej tradycyjną, ale też skuteczną metodę dostosowywania wstępnie przetrenowanych modeli, aby osiągnąć wyższą wydajność w określonych zadaniach.
Wybór między nimi zależy od konkretnych wymagań zadania, w tym potrzeby aktualnych informacji, dostępności odpowiednich wstępnie przetrenowanych modeli oraz zasobów obliczeniowych, które są do dyspozycji.
Najczęściej zadawane pytania
Jaka jest główna zaleta RAG w porównaniu z tradycyjnymi metodami?
Główną zaletą RAG jest zdolność dynamicznego uwzględniania ogromnych ilości zewnętrznych, potencjalnie aktualnych informacji w wynikach modelu, co zwiększa jakość i trafność generowanych treści.
Czy fine-tuning można zastosować do każdego wstępnie przetrenowanego modelu?
Tak, fine-tuning można zastosować do każdego wstępnie przetrenowanego modelu, o ile dostępna jest wystarczająca ilość danych specyficznych dla zadania, aby efektywnie przetrenować model.
Czy RAG jest bardziej intensywny obliczeniowo niż fine-tuning?
Zasadniczo RAG może być bardziej intensywny obliczeniowo niż fine-tuning, zwłaszcza jeśli dotyczy dużych, zewnętrznych baz danych i złożonych mechanizmów wyszukiwania. Jednakże konkretne wymagania obliczeniowe zależą od skali zadania i efektywności implementacji.


